La plate-forme CoderPad Interview vous permet de créer des bases de données personnalisées et de les associer à des questions afin d'évaluer les compétences d'un candidat en matière de traitement de données. Cliquez sur un élément de la table des matières ci-dessous pour en savoir plus sur l'utilisation de notre fonctionnalité de création de base de données.
Par exemple, un Node pad exécute une application Node.js Express avec une connexion intégrée à une base de données PostgreSQL. Nous avons également installé Sequelize, un outil ORM basé sur des promesses qui simplifie les interactions avec la base de données. Vous trouverez plus de détails dans le fichier server.ts. Pour configurer une base de données dans un Node pad, vous pouvez soit exécuter un script d'initialisation de la base de données, soit le faire via un point de terminaison API, comme ceux figurant dans server.ts.
Création d'une base de données personnalisée
Vous pouvez télécharger des bases de données personnalisées et les joindre à des questions pour tester la capacité d'un candidat à gérer, écrire et modifier des requêtes de base de données, soit en utilisant SQL, soit en utilisant un ORM ou un adaptateur.
✅ Les bases de données personnalisées dans CoderPad Interview sont disponibles pour MySQL et PostgreSQL.
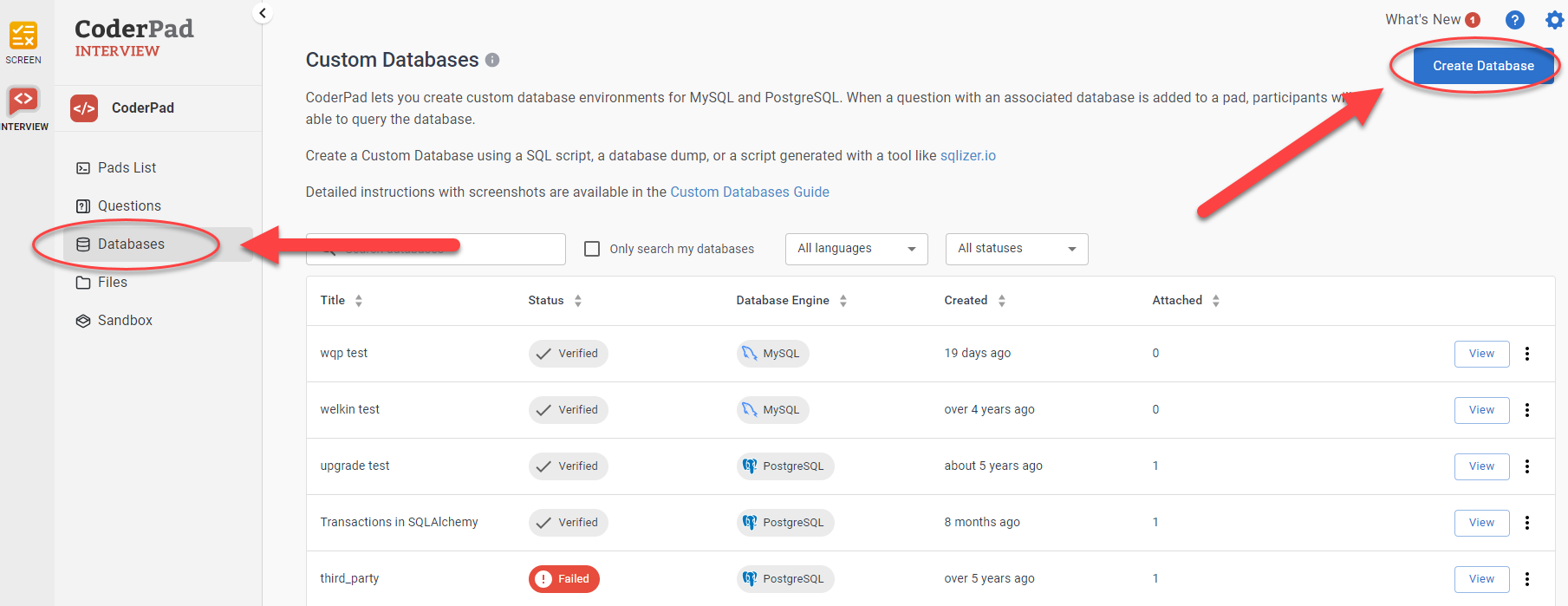
Pour commencer, accédez à votre tableau de bord dans CoderPad Interview et cliquez sur Bases de données dans la barre de navigation de gauche pour accéder à la page Bases de données personnalisées. Cliquez ensuite sur Créer une base de données.
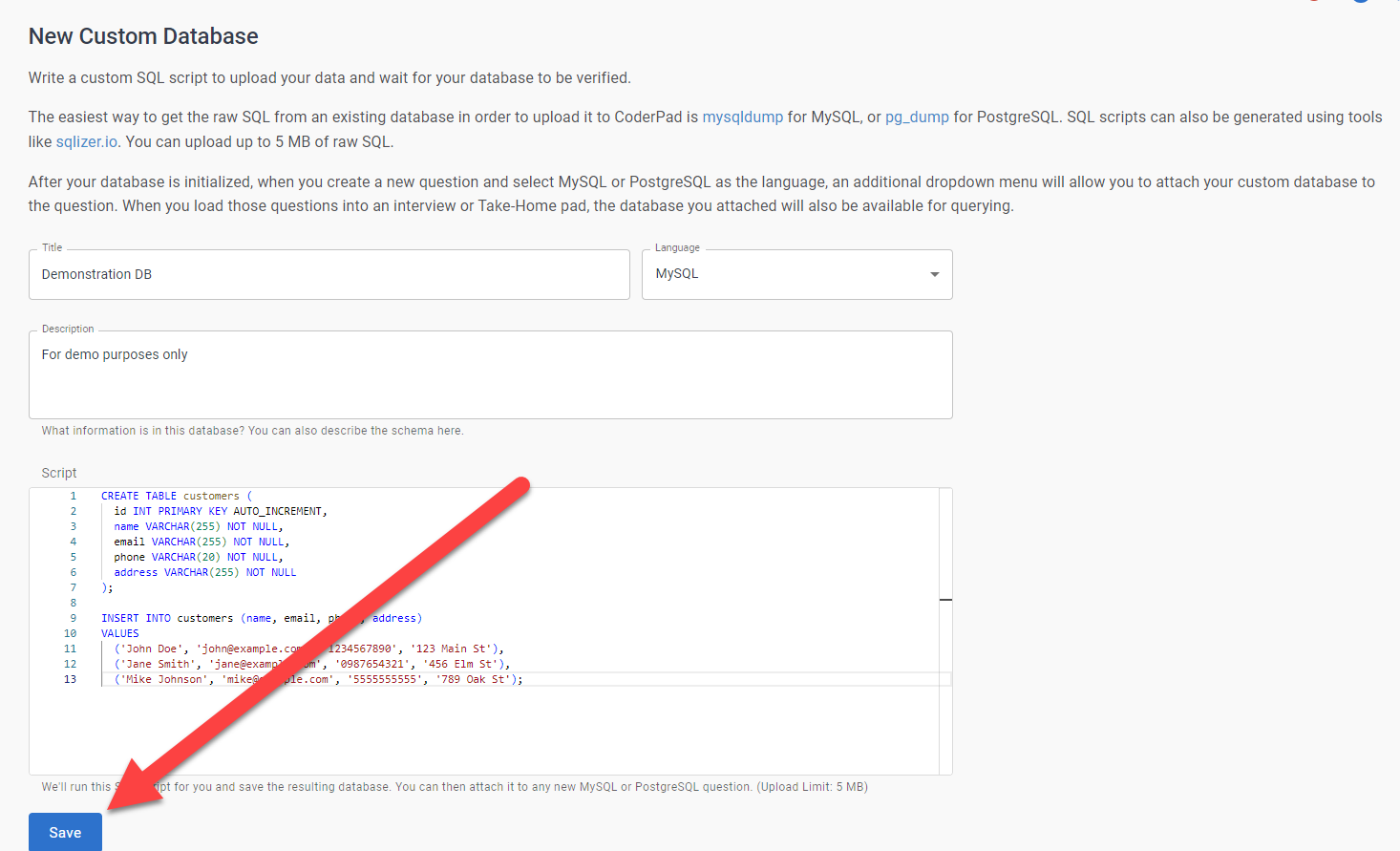
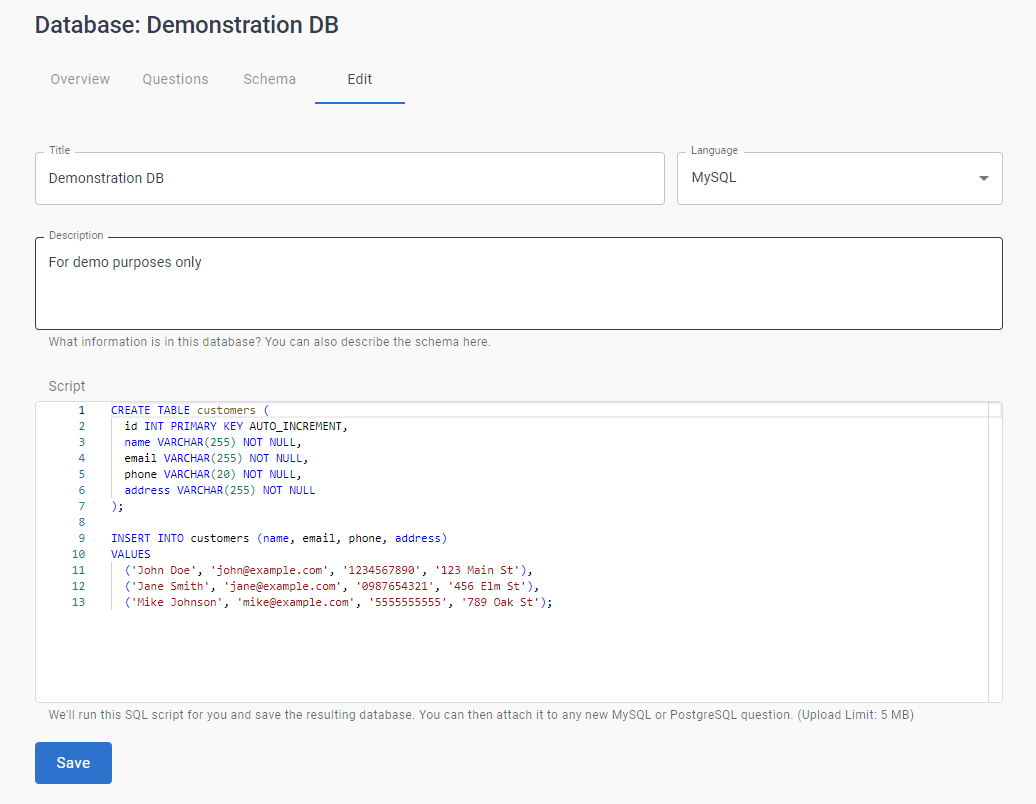
Ajoutez un Titre, une Description et sélectionnez MySQL ou PostgreSQL dans la liste déroulante Langue.
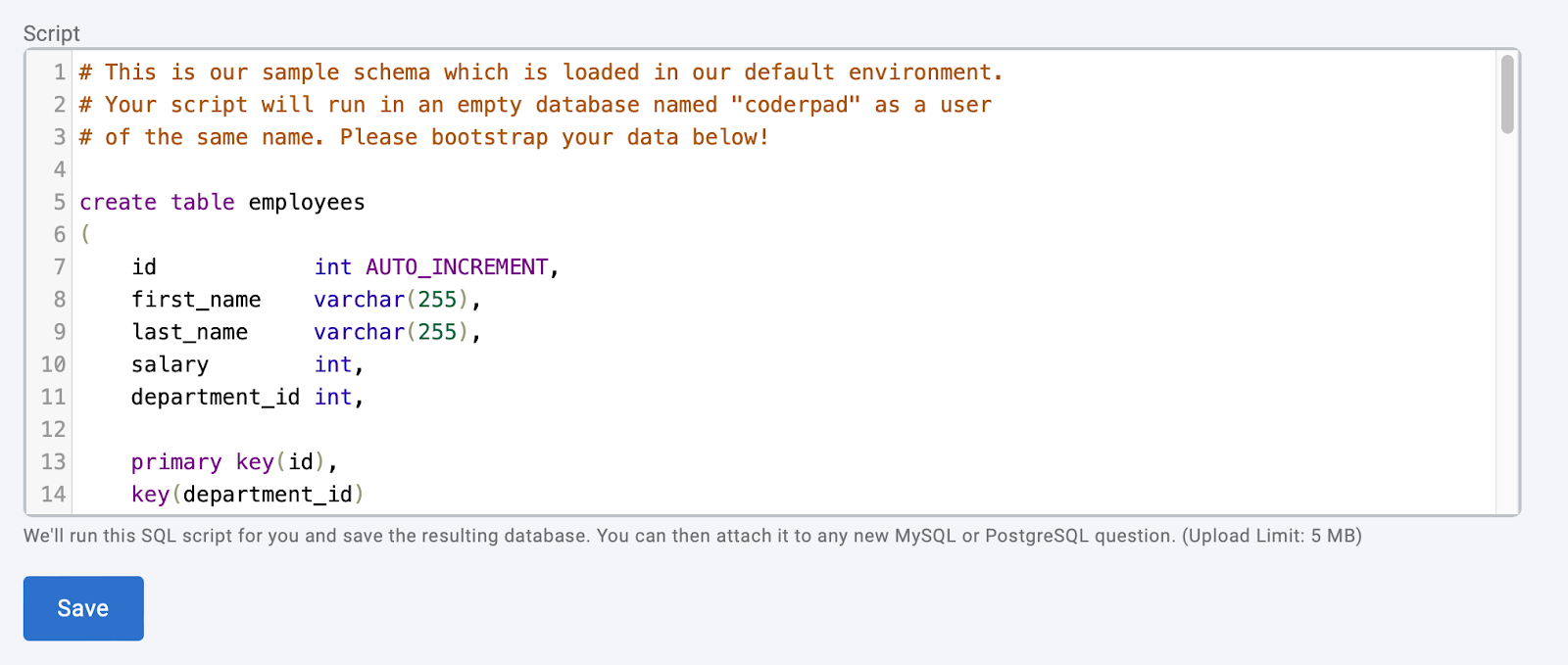
En dessous, vous verrez s'afficher le script SQL qui créera la base de données d'exemple. Vous pouvez le modifier selon vos besoins pour créer la base de données que vous souhaitez ; vous pouvez également copier/coller le SQL d'une base de données existante dans la zone de texte pour une personnalisation plus poussée.
CoderPad Interview fournit un exemple de script pour la création d'une base de données qui comprend des lignes relatives aux salariés, aux projets et aux services.
La façon la plus simple d'obtenir le code SQL brut d'une base de données existante afin de le télécharger sur Interview est d'utiliser mysqldump pour MySQL, ou pg_dump pour PostgreSQL. Vous pouvez télécharger jusqu'à 5 Mo de SQL brut.
Vérifiez que tout a bien été paramétré et cliquez sur Save pour créer votre base de données.
Vous verrez alors apparaître une notification indiquant que votre base de données est en train de s'initialiser.
❗Si vous voyez apparaître un message d'erreur, cela signifie que votre SQL est structuré de manière incorrecte. Veuillez corriger les erreurs et réessayer.
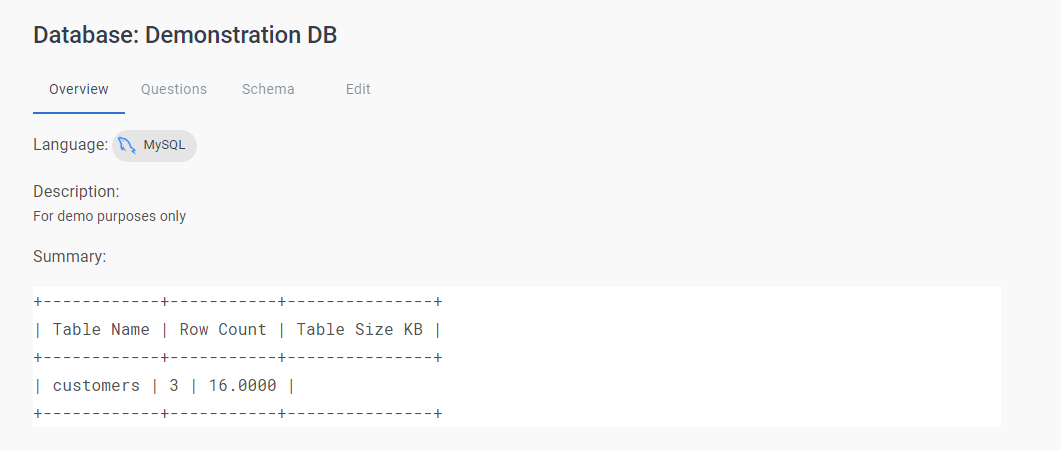
Une fois la base de données initialisée, vous verrez s'afficher l'onglet Overview qui vous donnera un aperçu de votre base de données personnalisée.
Vous verrez également apparaître les onglets suivants.
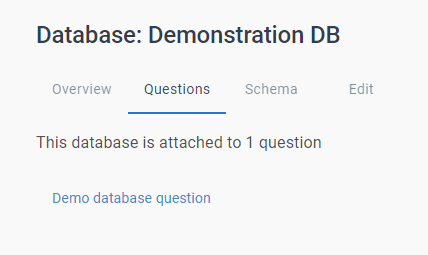
Questions
L'onglet Questions affiche toutes les questions auxquelles la base de données est associée.
En cliquant sur la question, vous l'ouvrez dans le tableau de bord de la banque de questions.
Schéma
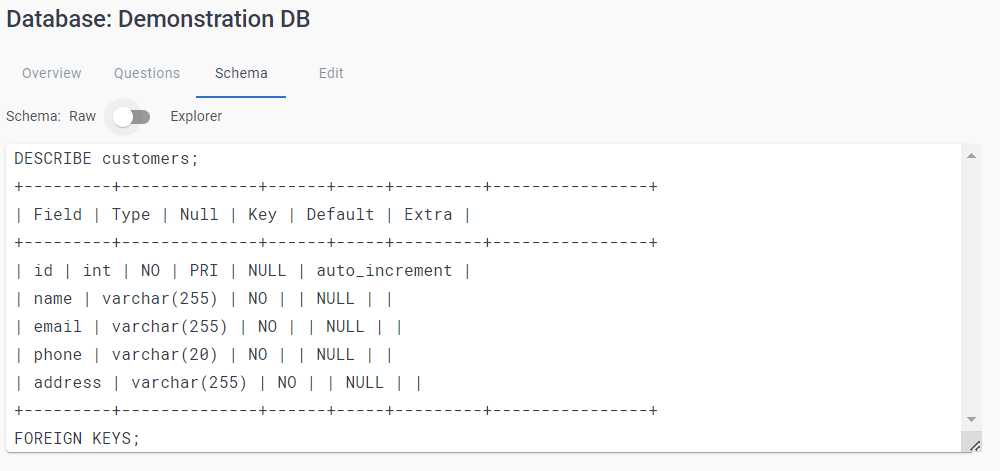
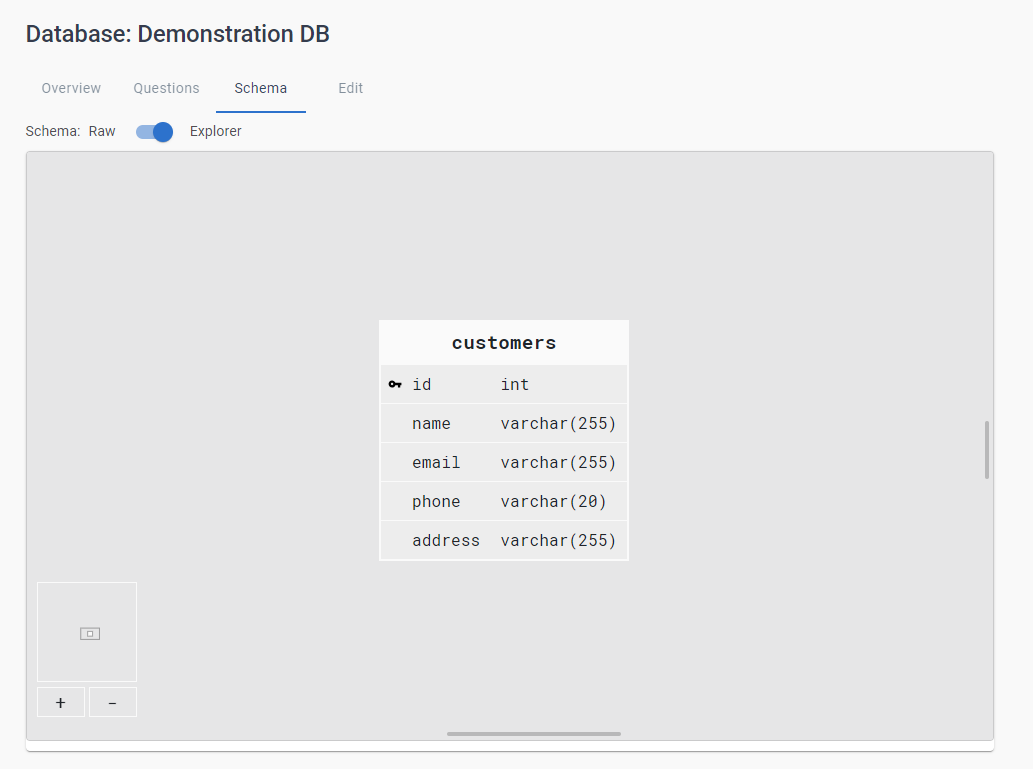
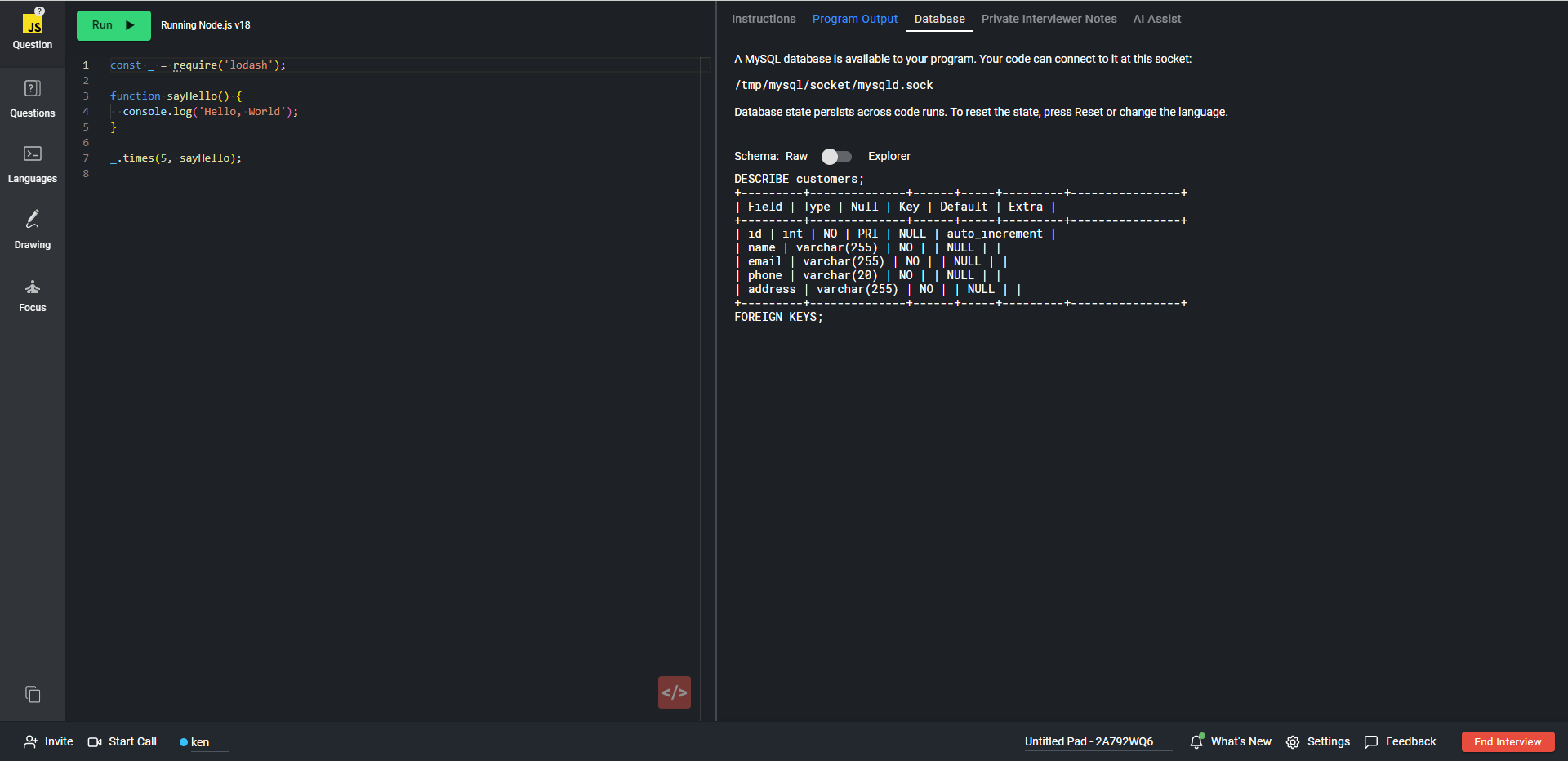
L'onglet Schéma affiche le schéma de la base de données. Vous pouvez basculer entre la vue Explorer et la vue Raw à l'aide de la bascule située en haut de l'écran.
La vue Raw affiche la définition du schéma SQL standard :
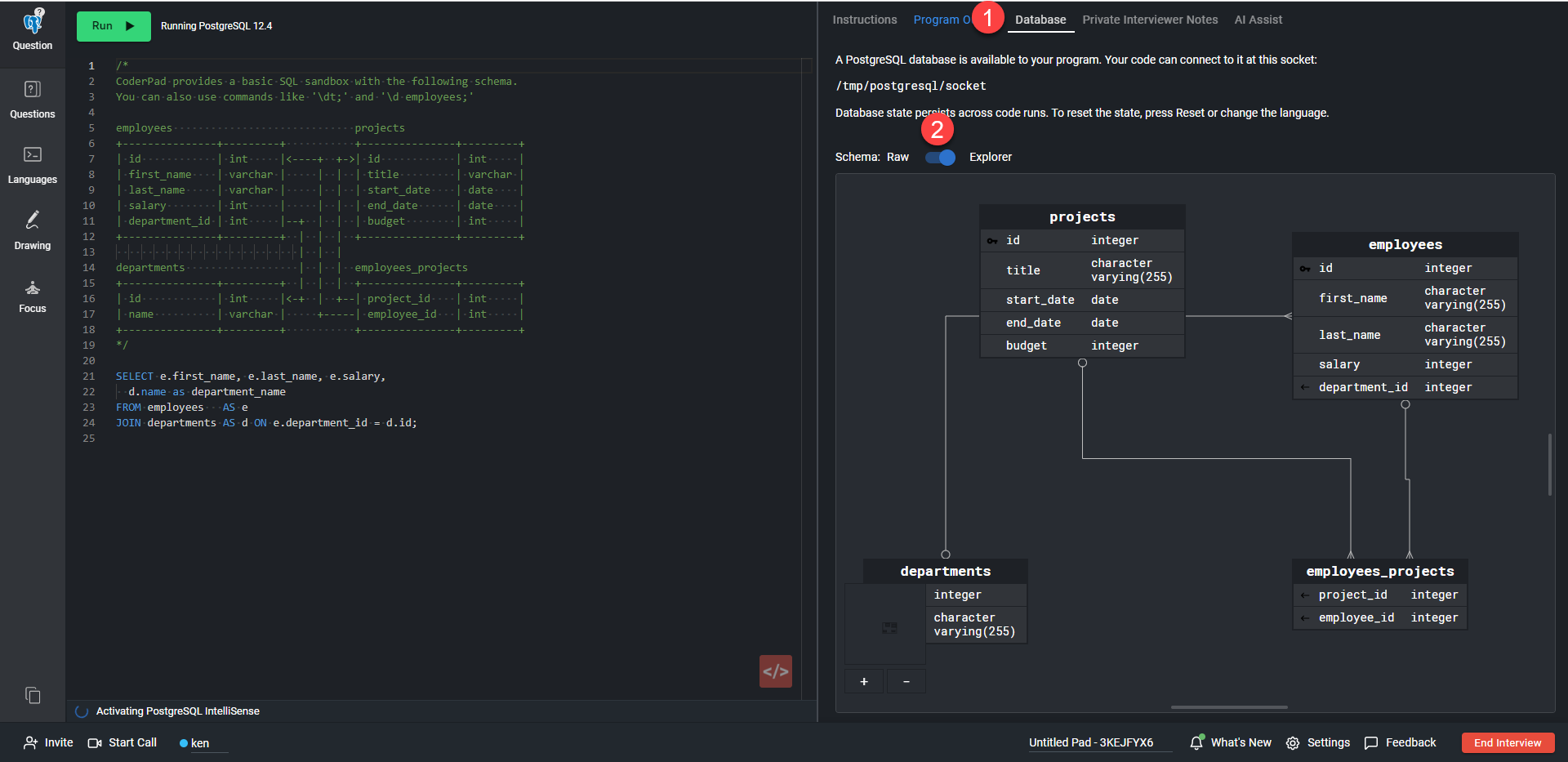
La vue Explorer affiche une représentation graphique de la base de données avec les tables et les relations entre les tables. Vous pouvez effectuer un zoom avant ou arrière et cliquer sur l'écran pour vous déplacer dans le schéma.
Le recruteur et le candidat peuvent utiliser les vues Raw et Explorer dans le pad.
Edit
L'onglet Edit ouvre la page de personnalisation afin que vous puissiez apporter toutes les modifications nécessaires à votre base de données.
✅ Vous pouvez accéder aux options des onglets Overview, Questions, Schema, et Edit à tout moment en naviguant vers la page Base de données personnalisée à partir du menu de navigation de gauche, puis en cliquant sur le bouton View de la base de données à laquelle vous souhaitez accéder.
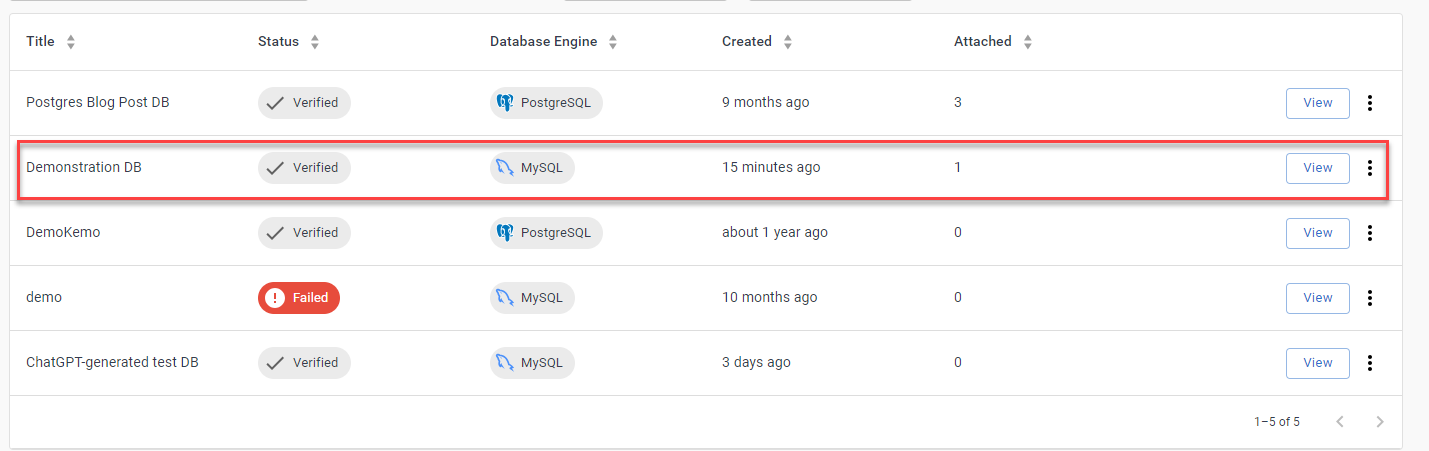
Dans l'onglet Bases de données du tableau de bord, vous verrez maintenant apparaître votre nouvelle base de données dans la liste des bases de données personnalisées disponibles.
⚠️ Pour supprimer une base de données, il vous suffit de cliquer sur les trois points situés à droite de la ligne et de sélectionner Delete. N'oubliez pas que cette opération est définitive.
Ajouter une base de données à une question
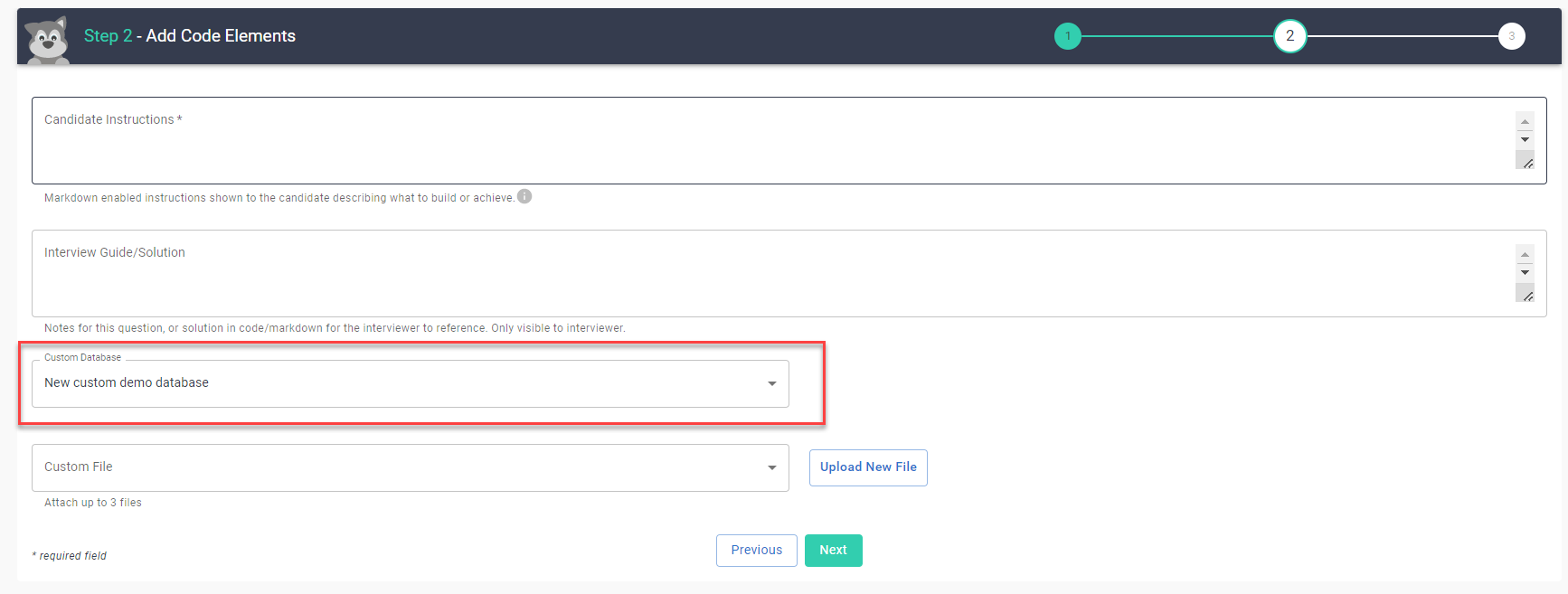
Les bases de données personnalisées doivent être associées à une question de la banque de questions. Vous pouvez le faire à l'Étape 2 - Ajouter des éléments de code de notre processus de création/modification de la question, en sélectionnant simplement votre base de données dans le menu déroulant Base de données personnalisée.
Lorsque vous chargez la question dans un pad, la base de données sera disponible et pourra être interrogée directement via MySQL/PostgresSQL, ou via un ORM/adaptateur pour les langages qui en disposent.
Accès à la base de données dans l'entretien
Une fois que vous avez créé votre question et votre base de données personnalisée, la base de données est automatiquement accessible lorsque vous créez le pad.
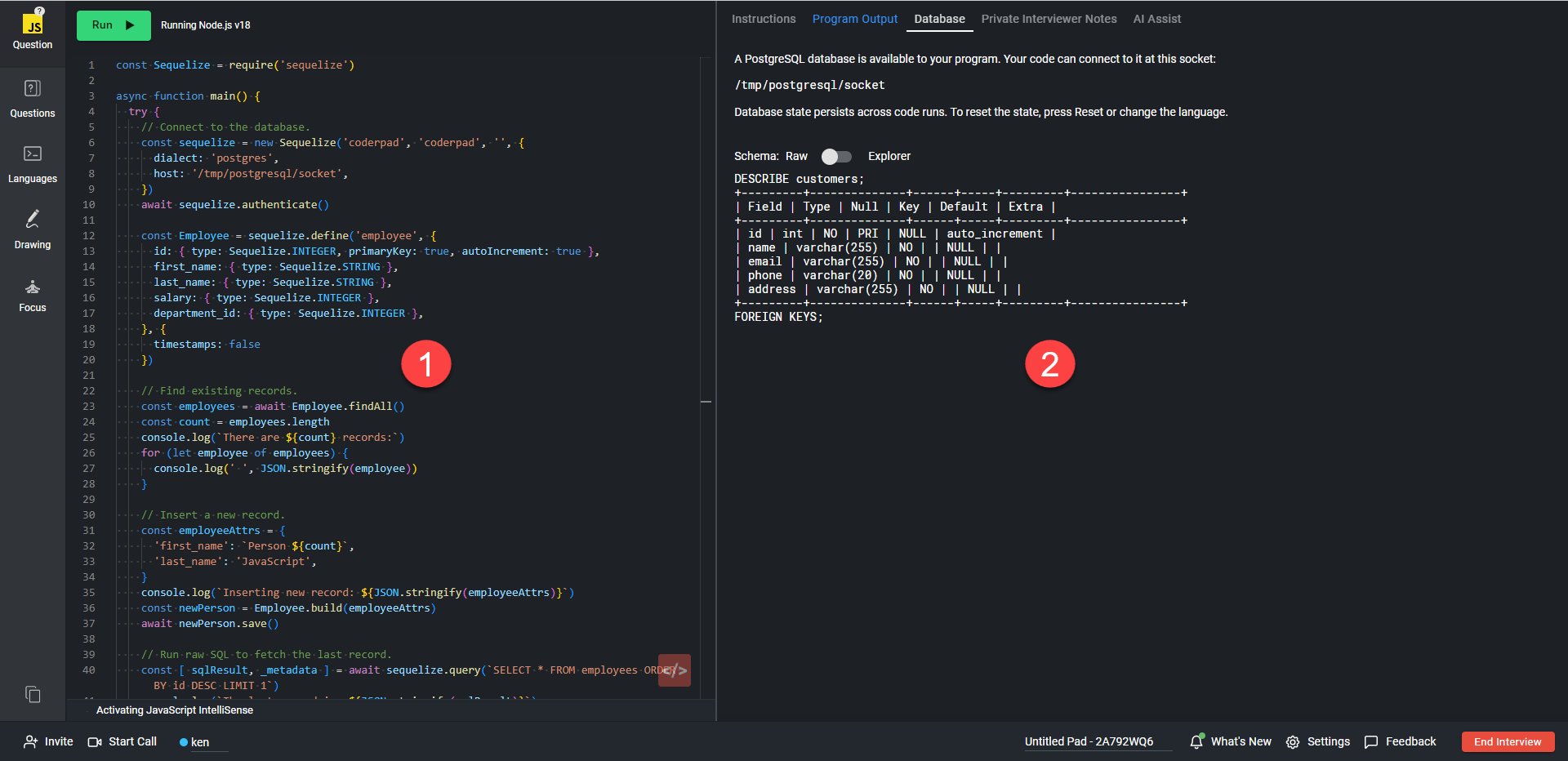
L'intervieweur et le candidat auront accès au schéma de la base de données dans l'onglet Base de données situé en haut du volet droit de pad (1). Vous pouvez passer du mode Raw au mode Explorer à l'aide du bouton de basculement (2).
Comme dans l'étape de création de la base de données ci-dessus, en mode Explorateur, vous pouvez effectuer un zoom arrière sur le diagramme et cliquer sur le bouton droit de la souris et le maintenir enfoncé pour vous déplacer sur l'écran :
En ce qui concerne l'accès aux données de la base de données, il y a deux façons de le faire dans le pad :
CoderPad Interview fournit des bibliothèques d'ORM et d'adaptateurs communes afin que vous puissiez interroger directement les bases de données à partir d'environnements non liés aux bases de données. Par exemple, vous pouvez demander aux candidats de charger des enregistrements SQL et d'interagir avec eux en Python, ou de faire la démonstration de leurs compétences en ActiveRecord dans l'environnement Ruby.
Cette fonction est disponible pour les langages les plus couramment utilisées dans CoderPad Interview, qui sont préconfigurées avec les adaptateurs indiqués ci-dessous. D'autres langages peuvent être ajoutés en fonction des besoins du client.
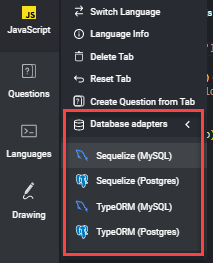
Pour configurer l'accès aux données via un adaptateur, vous devez d'abord sélectionner l'un des langages pris en charge dans la liste déroulante correspondante.
Une fois que vous avez fait cela, vous verrez un nouveau menu intitulé Adaptateurs de base de données apparaître à côté du langage sélectionné ; ce menu charge automatiquement l'adaptateur de base de données.
Cliquez sur la liste déroulante, et choisissez si vous souhaitez utiliser l'adaptateur MySQL ou PostgreSQL . La sélection d'un adaptateur charge automatiquement des exemples de code adaptateur/ORM dans le volet de gauche (1). Vous pouvez voir le schéma de votre base de données dans le volet de droite sous l'onglet Database (2) :
❗Le chargement du code de l'adaptateur de base de données commente tout le code existant, y compris le code de la question. La meilleure solution consiste à charger la question au début de l'entretien, ce qui impliquera peut-être de réorganiser un peu le code une fois que vous aurez chargé l'adaptateur. Cette approche offre la plus grande flexibilité dans le choix du langage dans lequel est mené l'entretien du candidat, ou de l'adaptateur de base de données.
✅ Si vous n'avez pas de base de données attachée à une question lorsque vous sélectionnez un package d'adaptateurs, le pad charge une base de données type.
Gardez à l'esprit que le package d'adaptateur est uniquement là pour vous mettre le pied à l'étrier. Comme mentionné ci-dessus, vous avez également la possibilité de coller le code de l'adaptateur lors de la configuration d'une question. Cela vous permet de sauter l'étape de chargement du package, car la base de données sera alors chargée avec la question, et non avec le package.
Cela vous oblige à sélectionner un langage et un adaptateur particuliers pour le candidat lors de l'élaboration de la question, ce qui laisse moins de flexibilité au moment de l'entretien.
Via SQL :
Les candidats peuvent écrire et exécuter des requêtes SQL pour interagor avec la base de données lors de l'entretien dans l'éditeur de code. Une fois que vous avez sélectionné votre version de SQL (MySQL ou PostgreSQL), aucune autre configuration n'est requise.
Rappels importants
Lorsque vous créez votre propre base de données personnalisée, la base de données originale est toujours sauvegardée et n'est jamais modifiée ; une copie est chargée pour chaque nouvelle session d'entretien.
Les modifications - telles que les insertions, les mises à jour et les suppressions de lignes - sont sauvegardées pendant la session d'entretien et persistent entre les exécutions de code ultérieures.
Vous pouvez réinitialiser la base de données pendant un entretien spécifique en appuyant sur le bouton Reset dans le coin supérieur droit.