The Differences Between Data Science And Data Engineering Job Roles

Whether charting a career, hiring the right talent, or staying updated with industry shifts, it is important to understand the similarities and differences between data science and data engineering.
The goal here is simple: to help you understand what data scientists and data engineers do, especially when scrolling through job listings and the terminology starts to blur together.
Even though these roles have “data” in the name, they’re not the same animal. And to make things even more interesting, the lines between them are getting fuzzier, thanks to all sorts of tech advancements.
In this article, we’ll break down the nitty-gritty of each role, explore why they’re starting to overlap, and give you some honest advice on keeping up in this ever-changing field. Ready to jump in?
🔖 Related resource: Jupyter Notebook for realistic data science interviews
1: The traditional understanding of data science and data engineering
The roles and responsibilities traditionally associated with data engineering and data science serve as a guiding framework for professionals and organizations. However, these traditional descriptions are rooted in a “classic” view – we will see later that both fields are ever-evolving, and the boundaries are more flexible than they once were.
Data science
Data science is an interdisciplinary field that employs various techniques, algorithms, and processes to extract valuable insights from structured and unstructured data.
However, this field goes beyond the mere application of algorithms and machine learning models; it also incorporates scientific methods that require a deep understanding of the data. Data science involves formulating hypotheses, applying appropriate statistical tests, and interpreting the results to derive actionable insights.
Data science is not merely a technical discipline but an integration of methods that require a scientific temperament. Beyond the algorithms and codes lies the essence of inquiry, exploration, and discovery. It’s about asking the right questions, challenging assumptions, and iterating based on evidence. In this light, data science transcends its technical roots, encapsulating a holistic methodology reminiscent of traditional scientific fields.
Data engineering
Data engineering, on the other hand, focuses on the practical aspects of data handling. This field creates and maintains the architecture, allowing data collection, transformation, and storage.
Data engineering serves as the foundational layer upon which data science operates. Data engineers often play a significant role in setting the stage for the smooth deployment of applications. However, deployment itself can be a collaborative effort. Sometimes, roles such as machine learning engineers and specialized DevOps teams come into play.
With the frameworks and pipelines data engineers establish, data scientists would find it easier to perform their analyses efficiently. Data engineering can be viewed as the backbone that supports the data science function, ensuring that data is readily available, clean, and in a format that can be easily manipulated for analytical purposes.
The radar chart below represents a general perspective of the competencies of data engineering and data science roles. Both professions showcase foundational data skills — data engineering related to infrastructure tasks and data science lean towards analytical and scientific expertise.
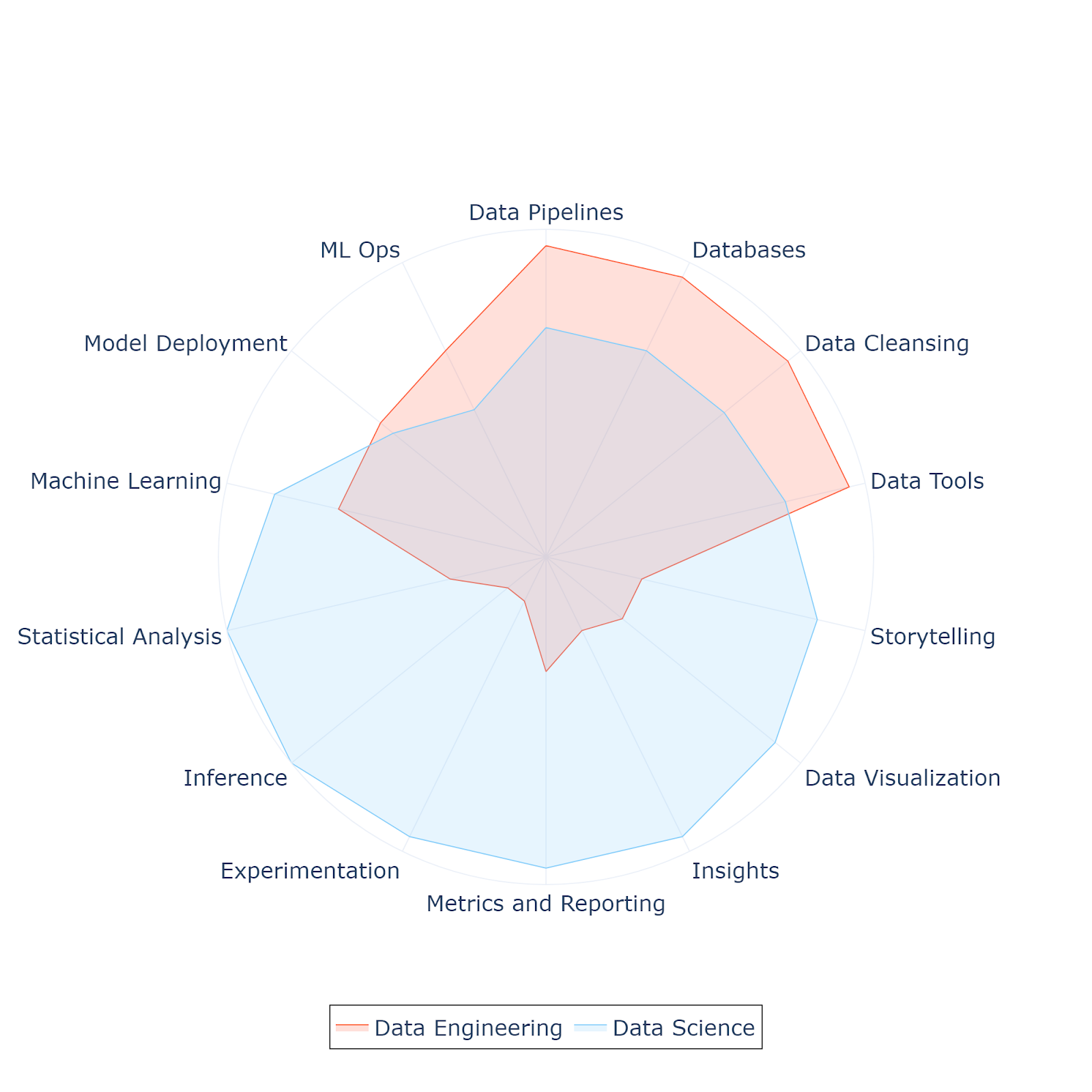
2: Shifting boundaries between data engineering and data science
The traditional definitions we discussed earlier provide a solid starting point, but the landscape is shifting. The roles of data scientists and data engineers are not strictly categorized.
The gray areas
In the evolving data ecosystem, one can’t help but notice the increasing overlap between data science and data engineering skills.
It’s becoming less rare to encounter data scientists who are not just analyzing data and training models but are also involved in setting up and managing data pipelines. For instance, consider a scenario where a data scientist is building a real-time machine-learning model for fraud detection in online transactions. To ensure the timely processing of each transaction, the scientist might need to design a custom data pipeline that efficiently fetches, preprocesses, and feeds transaction data to the model.
Conversely, a data engineer working on a platform for personalized content recommendations might need a foundational understanding of data analytics and statistical modeling. This would allow them to design a system that can efficiently gather user behavior data and feed it into recommendation algorithms, ensuring that data scientists can fine-tune models effectively.
But what’s driving this convergence of job responsibilities?
The catalysts of change
Technological advancements play a central role in reshaping the dynamics between these professions. The surge in innovative tools and platforms has democratized many aspects of data handling, allowing professionals to venture beyond their traditional scopes.
Take cloud computing, for instance. AWS, Google Cloud, and Azure have revolutionized data storage and processing. With their user-friendly interfaces and myriad services, data scientists find it easier than ever to set up databases, manage data streams, or even deploy machine learning models without heavy reliance on data engineers.
Moreover, the rise of platforms offering “Data Science as a Service” (DSaaS) further blurs the lines. These platforms provide end-to-end solutions, from data ingestion to model deployment, demanding a more holistic skill set from their users. AI’s influence in enhancing these platforms, offering real-time suggestions and automation capabilities, cannot be overstated.
3: Adapting to a rapidly changing landscape
If there’s one constant in the world of data, it’s change. The pace of innovation and the introduction of new technologies ensure that the data landscape is continually evolving. The dynamic field brings opportunities and challenges, requiring data professionals to be agile and committed to continuous learning.
The importance of continuous learning
The ability to adapt and grow is not just an asset. It’s a necessity. The onus is on professionals to keep their skills updated and stay attuned to industry shifts. At the same time, recruiters must recognize and value these evolving skills, understanding that today’s sought-after expertise might differ from tomorrow’s.
Tips for keeping up-to-date
So, how do you stay caught up whether hiring or being a job seeker? Here are some actionable tips:
- Online courses: Many platforms offer specialized data science and data engineering courses. These can be invaluable for learning new skills or updating your existing knowledge. Protip: Just make sure the course you’re into is up-to-date. For those looking to sharpen their coding skills or experiment in a real-time environment, consider tinkering in the CoderPad sandbox.
- Workshops and boot camps: These provide hands-on experience and are often more focused and cutting-edge, helping you quickly gain practical skills.
- Industry publications: Staying current means knowing what’s happening in the industry. Follow reputable publications and journals to inform yourself about the latest trends and research.
- Networking: Connect with peers and industry experts through social networks, conferences, and webinars. These interactions can provide insights and expose you to different perspectives.
- The key is to stay technologically curious: New tools and methods emerge constantly. Keep an eager eye on evolving technologies and methodologies. For recruiters, this means understanding the significance of new tools when they appear on resumes. For data professionals, it’s about mastering them.
Building on timeless foundations
Despite the constant evolution of the data realm, certain foundational pillars remain unchanged. These core competencies are the bedrock that stabilizes one’s journey through the shifting sands of data science and data engineering.
- Essentials of data structures and algorithms: A robust understanding of data structures and fundamental algorithms ensures optimal data manipulation and processing, irrespective of the tools in use. Tackle programming challenges on platforms like CodinGame.
- Statistical and mathematical mastery: The essence of data science lies in statistics and mathematics. Grasping core statistical concepts and linear algebra forms the basis for more advanced techniques.
- Programming proficiency: Command over programming languages, be it Python, R, SQL, C++, or JavaScript, is indispensable. While tools may evolve, the logic and reasoning behind programming endure.
- Data intuition: it’s about developing a sixth sense for data: recognizing patterns, understanding its nuances, and asking the right questions. It’s an art honed over time.
- Foundational system design: Understanding system interactions and scalability is crucial for data engineers. As data demands grow, this knowledge ensures the infrastructure evolves in tandem. Study architectural designs of successful systems, attend workshops, and seek mentorship from seasoned professionals.
- Ethical grounding: With great data power comes great responsibility. An ethical foundation, considering biases, privacy, and broader societal impacts, is paramount.
While adapting to the changing landscape is vital, anchoring oneself in these foundational skills ensures resilience and depth in one’s data journey. They provide the stability needed to navigate the complexities of ever-evolving technologies.
4: The complementary nature of data skills
Understanding data science and data engineering as separate fields is only one puzzle piece. These roles exist within a broader data ecosystem, functioning as complementary pieces, each empowering the other.
Above all, success isn’t merely determined by distinct roles but by the competencies individuals bring to the table. A seamless fusion of data engineering and data science skills is of prime importance for driving impactful results.
How data engineering competencies support data science tasks
For data professionals: Understanding the symbiotic relationship between data engineering competencies (like crafting robust data infrastructures) and data science tasks (like deriving insights) is crucial.
Imagine trying to analyze data that’s poorly structured or not easily accessible. It’s akin to deciphering a book with jumbled pages. Mastery in both areas ensures that data initiatives have a solid foundation and deliver actionable and timely insights.
For recruiters: When hiring, it’s essential to look beyond traditional role titles and focus on the competencies candidates bring. Overemphasizing one skill set while neglecting the other can lead to challenges:
- Inefficient data processing: Without competencies in setting up agile data pipelines, real-time analytics or handling of large datasets can become cumbersome, regardless of one’s proficiency in data analysis.
- Poor data quality: Effective data analysis relies on clean, structured data. Lacking data curation and management competencies can result in flawed or misleading insights.
- Increased costs: Addressing issues after they arise is often more resource-intensive. If someone adept in data analysis has to pause to address infrastructure issues, it prolongs timelines and increases costs.
As the lines between roles blur, a holistic approach emphasizing a blend of competencies in data engineering and science becomes the gold standard for successful data initiatives.
A spectrum of data competencies
It’s not just a binary distinction between data engineering and data science competencies. There’s a spectrum of skills and expertise that individuals might possess. For instance, many professionals, regardless of their title, might lean heavily into data interpretation, bridging the gap between raw data and actionable insights. This competency, often associated with data analysts, emphasizes understanding and translating data patterns into tangible business strategies.
Similarly, another sought-after competency is the ability to code algorithms that enable computers to learn from data and make decisions. While traditionally linked to machine learning (ML) engineers, this skill is becoming essential across many data roles. It involves building on foundational data handling and analysis competencies to create automated, data-driven solutions.
Enter MLOps competencies, which have become increasingly critical to an organization’s data policies and processes. These skills revolve around streamlining the machine learning lifecycle, from model development to deployment and monitoring.
Professionals adept in MLOps ensure that machine learning models are accurate, scalable, maintainable, and seamlessly integrated into production environments. Additionally, with the modern trend of agile workflows in data teams, mastering Continuous Integration and Continuous Deployment (CI/CD) practices has become a necessary competency, facilitating rapid and reliable model updates in production.
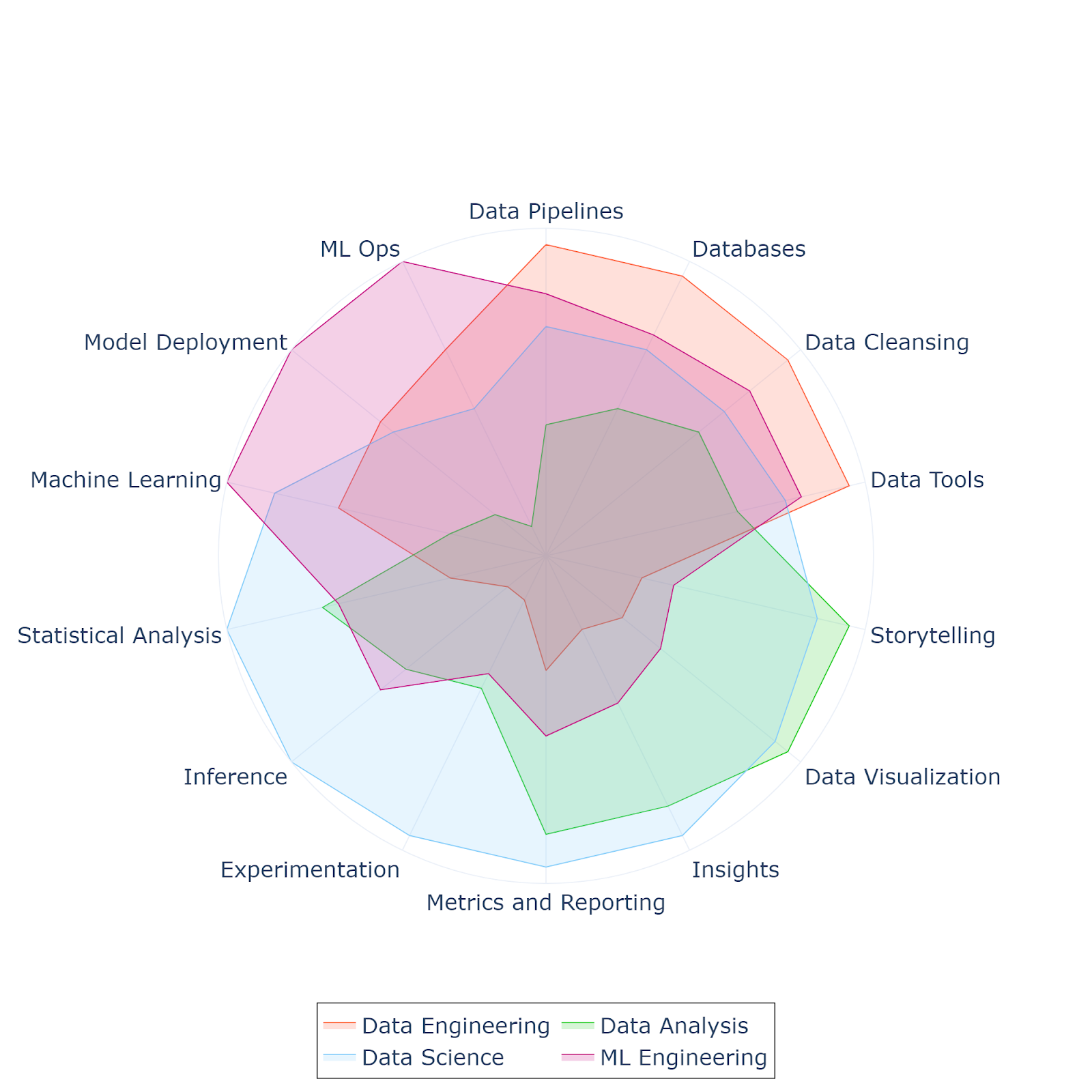
This visualization presents a comparative view across four pivotal data fields: data engineering, data analysis, data science, and machine learning engineering, rather than specific roles such as data engineer or data scientist.
This distinction is vital because thinking about fields provides a broader perspective on the skill landscape. An individual can excel in specific competencies within an area without fitting neatly into a predefined role. Each field displays unique strengths with noticeable overlaps, highlighting the significance of interdisciplinary skills in the data domain.
For data professionals and recruiters, it’s essential to recognize that possessing every skill in the vast data landscape is nearly impossible. Just as in soccer, where not everyone is a scorer and lacking a goalkeeper spells trouble, it’s about building a balanced team. The focus should be on ensuring complementary skills at the team level, where each member’s expertise fills the gaps of another.
Domain expertise: The forgotten hero of data science
While foundational data skills are crucial, one of the distinguishing attributes of an exceptional data scientist is their expertise in the domain of the data they work with.
For instance, a data scientist in the healthcare sector should possess a deep understanding of health data, medical terminologies, patient care processes, and the nuances of clinical trials. Similarly, a data scientist working in the financial sector should be well-versed in trading dynamics, financial instruments, and regulatory norms.
This domain knowledge is not just about understanding the data. It’s about grasping its real-world implications, challenges, and opportunities.
Such domain expertise is invaluable. It ensures that insights derived are contextually relevant, biases and limitations of the data are recognized, and the solutions proposed are practical and actionable. Moreover, domain expertise fosters effective communication with other stakeholders, ensuring that data-driven solutions align with broader organizational goals and industry-specific challenges.
Data professionals should delve into their respective domains, leveraging industry-specific resources and collaborating with experts to amplify their analysis. For recruiters, assessing candidates on technical prowess and their understanding and experience within the industry is vital. Fusing data skills with domain expertise is the benchmark for effective data science in any sector.
5: Navigating job listings: A skill-centric approach
With a grasp on the spectrum of data competencies, you’re better equipped to discern job listings. However, translating this understanding to the practical realm of job applications and interviews can be tricky. Here’s a guide to help you focus on the skills and expertise employers are seeking.
Spotting key competencies in listings
Navigating job listings requires an astute eye for competencies, especially since the traditional boundaries of roles have become less distinct. Here’s a breakdown of terms and competencies to watch out for:
For data analysis and modeling:
- Statistical modeling: Harnessing data to predict or understand trends.
- Data analysis: Interpreting data to uncover meaningful insights.
- Machine learning: Leveraging algorithms for predictive modeling.
- Insight generation: Converting data into actionable strategies.
- Inference or predictive analytics: Foreseeing future events based on historical data.
- Data visualization: Graphically representing data insights.
For data infrastructure and management:
- Data pipelines: Creating and managing processes for data flow.
- Data storage: Tasks centered around maintaining databases.
- ETL processes: Extract, Transform, and Load processes for data preparation.
- Database management: Ensuring optimal database performance.
- Cloud computing: Expertise in AWS, Azure, or Google Cloud platforms.
- Data architecture: Overseeing the design and management of data structures.
Other essential competencies:
- Structured Query Language (SQL): Directly relates to database querying or management.
- Git: Highlights collaborative coding and software development aspects.
- Python (or other programming language): Indicates scripting, data manipulation, or machine learning tasks.
- Distributed File System (DFS): Managing datasets across multiple servers.
- Spark: Processing substantial datasets efficiently.
- Docker & Kubernetes: Pointing towards deployment and scaling of applications.
- Application Programming Interfaces (APIs): The role may involve software tool integration or data exchange.
Moreover, as previously emphasized, domain expertise is a cornerstone for many of these roles, especially for data scientists. A deep understanding of the specific industry or sector can be as crucial as technical acumen. Given this complex landscape, it becomes even more imperative to focus on competencies and domain knowledge rather than adhering strictly to job titles.
Beyond these competencies, don’t forget the multifaceted nature of roles like machine learning engineers, MLOps specialists, and data analysts. While each position has a distinct emphasis, there’s a significant convergence of skills. Also, don’t forget that the skills listed here might be incomplete and may soon become outdated.
Key questions to unearth role expectations
Whether you’re evaluating potential hires or considering a job offer, probing with the right questions can demystify role expectations. Here are some competency-focused queries:
For roles emphasizing data analysis and modeling:
- What are some recent projects that involved data modeling or predictive analysis?
- Intent: Gauge the depth and breadth of hands-on experience with core analytical tasks.
- How collaborative is the process between teams focusing on data infrastructure and data analysis?
- Intent: Understand the candidate’s/team’s exposure to interdisciplinary collaboration, which can be crucial in ensuring seamless data operations.
- Which statistical tools and programming environments are predominantly used?
- Intent: Ascertain familiarity with industry-standard tools and adaptability to potential new tools.
- What is your approach when faced with data anomalies or inconsistencies during analysis?
- Intent: Gauge problem-solving skills and diligence in ensuring data integrity.
- How do you communicate complex data findings to non-technical stakeholders?
- Intent: Understand the ability to translate technical insights into actionable business recommendations.
- Can you share an instance where your domain expertise significantly influenced a data analysis or modeling decision?
- Intent: Assess the candidate’s domain knowledge’s depth and practical application in data tasks.
For roles emphasizing data infrastructure and management:
- What systems are in place for data storage and retrieval?
- Intent: Ascertain understanding and experience with data architecture, especially concerning scalability and efficiency.
- How does the organization ensure data quality during ETL tasks?
- Intent: Assess the rigor and robustness of data processing and validation methods.
- Can you describe a time when you had to scale a data pipeline to handle a significant increase in data volume?
- Intent: Understand experience with scalability challenges and solutions.
- How do you handle data security and compliance, especially with regulations like GDPR or CCPA?
- Intent: Gauge awareness and implementation of data security best practices and regulatory compliance.
Such pointed questions clarify the role’s emphasis on specific competencies and shed light on the organization’s broader data strategy and culture.
Conclusion
Recognizing the evolving interplay and convergence between data science and data engineering domains is crucial. This article has highlighted the unique competencies of each while emphasizing their increasing intertwinement.
The key takeaway is the importance of adaptability and a continuous learning mindset based on solid, timeless foundations. As the lines between roles blur and technology advances, professionals should prioritize a competency-focused approach. It’s less about the exact role one holds and more about the diverse skills one brings.
In sum, the data realm is in constant flux, and success hinges on an interdisciplinary blend of skills, constant upskilling, and a deep appreciation of the changing data world. Embracing this holistic perspective ensures individuals and organizations remain at the forefront of data-driven innovation.
Additional resources to stay updated
- Reddit communities:
- /datascience: A vibrant community discussing various facets of data science, from beginner topics to advanced research.
- /dataengineering: Dive into the technical challenges and solutions that data engineers encounter, shared by both novices and experts.
- Online publications:
- Towards Data Science on Medium: This publication spans various articles on data science, machine learning, AI, and more, contributed by professionals and researchers globally.
- Podcasts:
- Data Skeptic: Kyle Polich hosts this insightful podcast, delving into the intricacies of data science, statistics, machine learning, and AI, often enriched by interviews with industry experts.
- Strong fundamentals with books:
- “The Pragmatic Programmer” by Andrew Hunt and David Thomas: A timeless classic that offers practical advice on software development best practices, this book is invaluable for anyone involved in coding, including data professionals.
- “The Visual Display of Quantitative Information” by Edward R. Tufte: Often regarded as one of the best books on data visualization, Tufte’s work is a must-read for understanding the art and science behind visually representing data.
- “Think Stats: Probability and Statistics for Programmers” by Allen B. Downey: A practical guide to statistics and probability using Python. This book focuses on real-world examples and exercises to teach programmers and data scientists essential statistical concepts.
- Keep your data science skills up-to-date by practicing a CoderPad Interview data question, like the one below.