SQL Functions and Techniques Every Data Person Should Know
Writing SQL queries that don’t utilize database features can cost developers a lot. The cost varies from spending more time writing tedious long queries or having a tech debt later on to debug the performance issue coming from the database server.
PostgreSQL has features that help you select data efficiently. These features can also help minimize the lines you write SQL queries.
In a previous tutorial, we discussed why and how to use window functions in PostgreSQL to aggregate data. However, this tutorial will show you what’s beyond aggregate functions, especially with the HAVING clause. You will also learn about subqueries and different types of JOINs.
Afterward, you will get familiar with features in PostgreSQL, like inheritance, full-text search, views, and how to handle geospatial data in PostgreSQL.
I encourage you to apply everything mentioned in this tutorial. You can use the CoderPad sandbox with the PostgreSQL playground to practice the commands learned in this article.
Aggregate functions (with HAVING clause)
An aggregate function is a function that groups a number of rows to form one record. Examples of aggregate functions in SQL are MAX, MIN, COUNT, and SUM. To filter the output of the aggregated result, you need a HAVING clause.
The HAVING clause is similar to the WHERE clause but for aggregate functions. To make it more clear, see the examples below!
An employee table has been created for the example queries in this section. Have a look at the employees table first before proceeding:
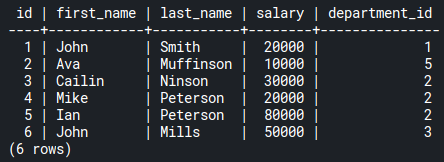
In the employees table above, you want to count the number of employees in each department.
You can use a GROUP BY clause for aggregation:
SELECT department_id, count(*) AS num_employees
FROM employees
GROUP BY department_id;Code language: SQL (Structured Query Language) (sql)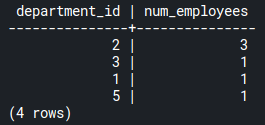
The number of employees in each department designated by their ID is shown in the image above.
What if you want to get the number of employees in the engineering department?
To answer this question, first, retrieve the id of the engineering department from the department table using this query:
SELECT *
FROM departments;Code language: SQL (Structured Query Language) (sql)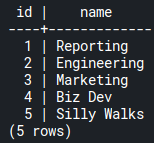
From the image above, the engineering department id is 2. If you filter the department_id that equals 2 in the first query, you’ll get the number of employees in the engineering department:
SELECT department_id, count(*) AS num_employees
FROM employees
GROUP BY department_id
HAVING department_id = 2;Code language: SQL (Structured Query Language) (sql)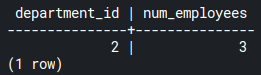
See another example where you want to get all departments where we have just a single employee. To do that, run this query:
SELECT department_id, count(*) AS num_employees
FROM employees
GROUP BY department_id
HAVING count(*) = 1;Code language: SQL (Structured Query Language) (sql)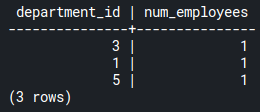
So the previous two queries showed how to use the HAVING clause. This is the clause we use to filter an aggregate function. The HAVING clause is followed by an aggregate condition. You can filter the column name by using =, <, >, or any comparison operator. You can also use an aggregate function in that condition, like the count() function in the previous query.
Subqueries
Sometimes your queries must have more than one SELECT statement. In such cases, you need subqueries.
Suppose you want to get employees’ salaries that are higher than the average. So you go ahead and get the average salary:
SELECT AVG(salary)
FROM employees;Code language: SQL (Structured Query Language) (sql)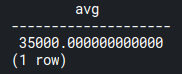
and then take note of that number and put it in this query:
SELECT *
FROM employees
WHERE salary > 35000;Code language: SQL (Structured Query Language) (sql)The problem in this process is that you have an intermediate step. You want to get rid of that manual step and do a one-query. That’s why you need a subquery which is, in this case, an internal query to calculate the average salary so that you can filter by it. Use a subquery as follows:
SELECT *
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Code language: SQL (Structured Query Language) (sql)So now selecting the average has become a subquery that we filtered the salary column with.
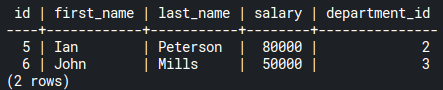
The previous two queries provide the same output:
You can also use subqueries to check the existence of records instead of filtering their values. Suppose you want to get employees who are not currently working on a project. You have two tables, employees and employees_projects. The latter table references each employee with their corresponding projects. Run SELECT * from each table to take a look!
Then, you could write a query like this:
SELECT e.first_name, e.last_name, e.salary
FROM employees e
WHERE e.id NOT IN (
SELECT ep.employee_id
FROM employees_projects ep
WHERE e.id = ep.employee_id
);Code language: SQL (Structured Query Language) (sql)This query gets the employee data where the employee ID does not exist in the list of values of employee_id‘s in the employees_projects table. This is not a very efficient query if you have a table with million records. That’s because you wouldn’t need the employee_id‘s values. Here you just need to check if they exist or not. In this case, you’ll need to return true values from the employees_projects table, which can be used by SELECT 1. You’ll also need to use the keyword EXISTS to check the existence of these true values. For our query, we would negate the existence using the NOT operator.
SELECT e.first_name, e.last_name, e.salary
FROM employees e
WHERE NOT EXISTS (
SELECT 1
FROM employees_projects ep
WHERE e.id = ep.employee_id
);Code language: SQL (Structured Query Language) (sql)The previous two queries provide the same output:
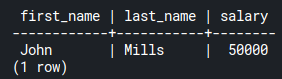
employees_projects table.As you can see, John Mills is the only employee who doesn’t have an ongoing project to work on.
Self joins
A self-join is used to join columns from the same table.
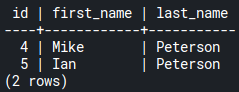
Let’s assume you want to retrieve employees who share the same last name:
SELECT e1.id, e1.first_name, e2.last_name
FROM employees e1, employees e2
WHERE e1.id <> e2.id
AND e1.last_name = e2.last_name;Code language: SQL (Structured Query Language) (sql)The FROM clause is followed by two tables; the same employees table. There are two conditions in the WHERE clause; ids are not the same, and the last names are the same.
The above short-hand comma syntax is equivalent to an INNER JOIN syntax (which we will illustrate later in this tutorial). So an equivalent query would be:
SELECT e1.id, e1.first_name, e2.last_name
FROM employees e1
JOIN employees e2 ON e1.last_name = e2.last_name
AND e1.id <> e2.id;Code language: SQL (Structured Query Language) (sql)OUTER joins
An OUTER join is the FULL_OUTER_JOIN. This join returns all records that meet the query condition, whether in the left table or in the right table.
To make sure you understand OUTER joins, experiment with the example below.
Assume you have a record inserted in the employees table that has an empty value in a specific column like this:
INSERT INTO employees(first_name, last_name, salary) VALUES('Ibrahim', 'Saeid', 15000);Code language: SQL (Structured Query Language) (sql)As you can see, Ibrahim Saied is added with a salary equal to 15000 but there was a little issue. He was not assigned to any department. In other words, the value of department_id in his record is NULL. Have a look at the new employees table running SELECT * FROM employees:
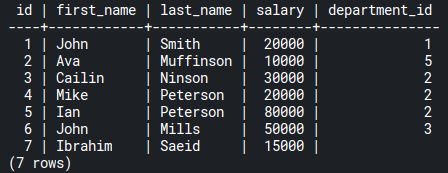
Have a second look at the departments table, and you’ll see that there is a department that has no employees, which is Biz Dev, with an id of 4. That’s because department_id has no value of 4 in the employees table.
Our task now is to list all employees’ names associated with their departments.
You can accomplish different outcomes to solve this task. You need to know what requirements you really want to accomplish. In this section and the section that follows, we will discuss different scenarios.
You need two tables; employees table to get employees names, and departments table to get departments names. That’s a given! but there are null values in each table!
To list all employees with their departments, including both Ibrahim Saeid and the Biz Dev department, use FULL OUTER JOIN:
SELECT e.first_name, e.last_name, e.salary, d.name AS department
FROM employees e
FULL OUTER JOIN departments d ON d.id = e.department_id;Code language: SQL (Structured Query Language) (sql)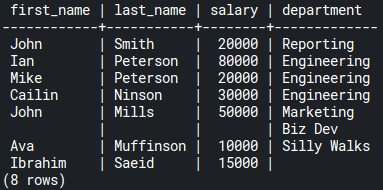
In the next section, we will discuss more scenarios.
INNER joins
An INNER join is the conventional SQL join. This join statement joins two tables that match on both sides, the left and right tables.
An INNER join has 3 types:
INNER JOINwhich returns all records that match the values in both tablesLEFT INNER JOINwhich returns all records that meet the query condition in the left table, but doesn’t meet that condition in the right tableRIGHT INNER JOINwhich is the reverse of theLEFT OUTER JOIN
💡You can omit the
INNERkeyword from each join statement.
So in the OUTER join query example mentioned in the last section, we saw that both null values, from the employees table and the departments table, were returned. For the INNER JOIN, the case is the reverse. You’ll get records that exist in both tables:
SELECT e.first_name, e.last_name, e.salary, d.name AS department
FROM employees e
JOIN departments d ON d.id = e.department_id;Code language: SQL (Structured Query Language) (sql)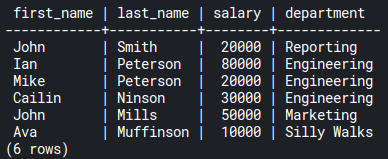
As you can see, there are no null values that match the join condition.
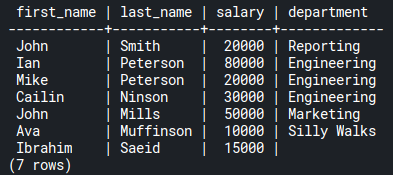
To list all employees with their departments, including Ibrahim Saeid, who is not in a department:
SELECT e.first_name, e.last_name, e.salary, d.name AS department
FROM employees e
LEFT JOIN departments d ON d.id = e.department_id;Code language: SQL (Structured Query Language) (sql)Here, we used LEFT JOIN because we started selecting the employees table. So the output would be:
To list employees with their departments, including the Biz Dev department, which has no employees, just change the previous query from LEFT JOIN to RIGHT JOIN:
SELECT e.first_name, e.last_name, e.salary, d.name AS department
FROM employees e
RIGHT JOIN departments d ON d.id = e.department_id;Code language: SQL (Structured Query Language) (sql)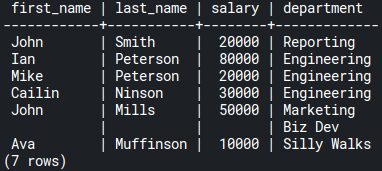
Run the sandbox below to test the new queries learned in this article:
Conclusion
The mentioned PostgreSQL features can help you write fewer lines of SQL and also write performant queries. Learning these concepts in PostgreSQL will help you in your PostgreSQL interview questions to write queries.
This tutorial discussed how to write aggregate functions (with a HAVING clause). We saw how to write subqueries and use them efficiently. You learned how to use self-joins, outer joins, and inner joins (including left and right joins).
You should also take a look at PostgreSQL System Catalogs, which is an advanced topic on PostgreSQL data analysis.
I’m Ezz. I’m an AWS Certified Machine Learning Specialist and a Data Platform Engineer. I help SaaS companies rank on Google. Check out my website for more.